Table of Contents
Tema 1 - Radix Tree
Data publicarii: 23.10.2013 Data ultimei modificari: 13.11.2013 Deadline: 17.11.2013 23:55 Responsabili: Tudor Scurtu, Radu Stoenescu
Obiective
- familiarizarea cu limbajul de programare Java
- familiarizarea cu diferitele concepte de baza ale POO
- fundamentarea practica a constructorilor si a agregarii
- respectarea unui stil de codare si de comentare
Enunt
Se cere implementarea unui Radix Tree [1] pentru indexarea cuvintelor dintr-un text.
Cerinte
- Punctul de intrare in program (clasa ce contine metoda main) va trebui sa se numeasca Index.java.
Platforma de testare se bazeaza pe acest punct de intrarea in vederea rularii testelor automate. - Programul va primi la intrare doua nume de fisiere - primul contine textul de indexat, iar al doilea contine pe fiecare linie cate un prefix.
Puteti gasi mai multe detalii in sectiunea de Precizari. - Programul va afisa la iesire, pe cate o linie, numarul de aparitii in text a fiecarui prefix din al doilea fisier primit la intrare, urmat de pozitiile cuvintelor in cadrul textului in care prefixul respectiv poate fi gasit.
Aceste numere trebuie separate prin spatii. Pozitiile cuvintelor incep de la 0. - Programul trebuie sa implementeze un Radix Tree si sa il foloseasca pentru cautare.
- Respectarea unui stil standard de codare - de exemplu stilul Google [2]. Conventia de nume din stilul Google este obligatoriu. Celelalte elemente de stil sunt la libera alegere, atat timp cat sunt folosite consistent.
- Comentarea codului [3][4][5][6] - se cere scrierea de javadocuri pentru toate clasele si pentru metodele netriviale, precum si comentarea blocurilor de cod netriviale. Nu abuzati de comentarii.
- Tema trebuie insotita de un document Readme in care se vor descrie detaliile implementarii, problemele aparute in cursul dezvoltarii si solutiile gasite, precum si modalitatile folosite pentru a testa codul.
Precizari
- Se poate dezvolta pe baza scheletului de cod atasat enuntului, sau se poate porni de la o noua implementare atat timp cat se respecta conditiile anterioare.
- Deoarece invatarea citirii din fisier nu face parte din obiectivele temei, se recomanda pornirea de la scheletul de cod atasat enuntului.
- La citirea textului din fisier se considera cuvant orice secventa maximala de caractere alfabetice si caracterul apostrof. Orice alte caractere vor fi ignorate. Pentru simplificare, toate caracterele alfabetice vor fi interpretate drept litere mici.
Corectare
!! Update - VMCHECKER !!
Vmchecker este functional si puteti sa va uploadati temele pe link de la resurse. Vmchecker compileaza sursele voastra asadar nu trebuie sa includeti in arhiva folderul bin. (chiar daca il puneti nu este nicio problema) Este important ca metoda main sa se afle in fisierul Index.java in clasa Index conform scheletului de cod. Arhiva voastra zip trebuie sa contina:
- src/ (directorul cu sursele voastre)
- Index.java
- AlteClase1.java
- AlteClase1.java
- doc/* (generat de javadoc)
- readme (in care explicati cum ati implementat tema)
Vmchecker utilizeaza aceleasi teste ca si cele de la resurse. Daca intampinati probleme, va rog folositi forumul pentru a intreba.
!! Update - Checker !!
La resurse puteti gasi checker-ul pentru tema 1. Continutul arhivei trebuie copiat in directorul proiectului din eclipse. Veti avea trei foldere:
- in - cu testele de input
- out - aici se vor salva outputurile programului vostru
- ref - aici sunt outputurile pe care ar trebui sa le obtineti
Exista 2 scripturi de testare: checker.bat (windows) si checker.sh (linux) Pe langa cele 2 scripturi, va mai fi si un fisier Comparator.class care va fi utilizat de checker pentru a compara output-ul vostru cu output-ul de referinta. Indicii nu trebuie neaparat afisati in ordine, ci pot fi afisati asa cum ii gasiti in arbore. Modul in care rulati checker-ul:
- Windows:
checker.bat <numele_clasei_ce_contine_main> - Linux:
./checker.sh <numele_clasei_ce_contine_main>
Exemplu:
checker.bat Main./checker.sh Main
Clasa voastra cu metoda main trebuie sa fie plasata in directorul bin din folderul proiectului. Ierarhia de fisiere ar trebui sa fie urmatoarea:
- Tema1RadixTree/
- bin/
- AltePachete1/
- AltePachete2/
- AlteClase1.class
- AlteClase2.class
- ClasaCuMetodaMain.class
- src/
- in/
- out/
- ref/
- checker.sh
- checker.bat
- Comparator.class
Checkerul acesta nu compileaza sursele voastre .java. El se asteapta sa le gaseasca in bin/ fiind compilate automat de eclipse. In cazul vmchecker, sursele voastre vor fi compilate de server.
Daca intampinati probleme, exista vreun test gresit sau aveti dificultati in a folosi testerul, va rog intrebati pe forum.
Tema se va corecta folosind platforma vmchecker [7]. Platforma va rula o suita de teste in cadrul carora implementarile temei vor primi la rulare diferite intrari, iar apoi iesirile generate vor fi comparate cu rezultate asteptate.
Daca platforma de testare nu acorda niciun punct solutiei, atunci acesta va fi punctajul final al implementarii temei.
Nerespectarea cerintelor 1. si 4. va avea drept rezultat acordarea a 0 puncte pe intreaga tema.
Se vor posta mai multe detalii odata ce vor fi finalizate.
_
Punctaj
80p - acordate de vmchecker pentru executia cu succes a suitei de teste 10p - acordate de asistent pe baza calitatii implementarii si a respectarii principiilor POO 10p - acordate de asistent pe baza lizibilitatii codului, a calitatii comentariilor si a fisierului Readme [2][3][4][5]
Resurse utile
[1] http://en.wikipedia.org/wiki/Radix_tree
[2] http://code.google.com/p/gtge/wiki/JavaCodeStyleGuideline
[3] https://www.clear.rice.edu/comp310/JavaResources/comments.html
[4] http://www.oracle.com/technetwork/java/javase/documentation/index-137868.html
[5] http://javarevisited.blogspot.ro/2011/08/code-comments-java-best-practices.html
[6] http://www.javacodegeeks.com/2011/07/funny-source-code-comments.html
[7] https://vmchecker.cs.pub.ro/
Schelet Tema 1
Update: 3:41pm 12.11.2013
Update: 4:52pm 12.11.2013 - Linux LF endings
Update: 7:01pm 12.11.2013 - Update pentru Java 1.5/1.6
Checker Tema 1
PDF enunț temă
Exemplu de rulare
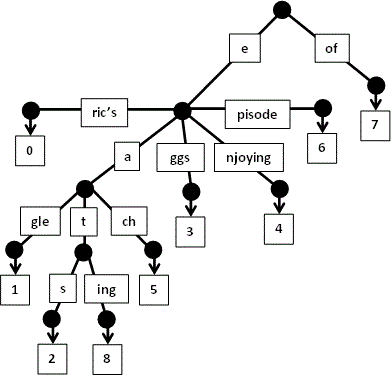
Continutul fisierului cu text:
Eric's eagle eats eggs, enjoying each episode of eating.
Continutul fisierului cu prefixe:
eggs eat
Iesirea asteptata:
1 3 2 2 8
Pasii rularii:
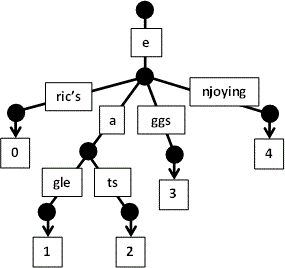
- se initializeaza arborele:

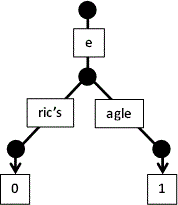
- se citeste
Eric's:

- se citeste
eagle:
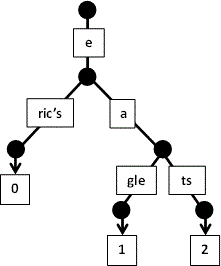
- se citeste
eats:
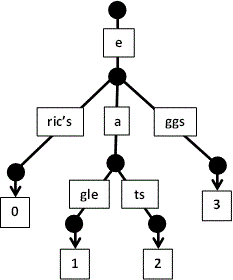
- se citeste
eggs:
- se citeste
enjoying:
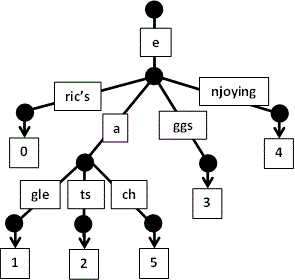
- se citeste
each:
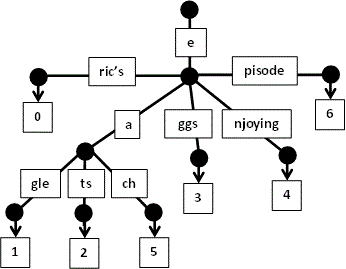
- se citeste
episode:
- se citeste
of:
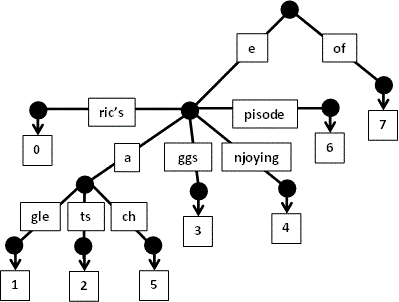
- se citeste
eating: